Creating Exceptional AI-Generated Art Through Enhanced Prompting
Written on
Chapter 1: Understanding Prompt Engineering
Creating compelling AI-generated images involves mastering the art of prompt engineering, particularly within frameworks like Stable Diffusion. This practice revolves around forming precise and clear instructions that a text-to-image model can interpret. Essentially, prompt engineering is about learning the "language" needed to instruct an AI on what to visualize. By refining these directives, we can produce more tailored and stylistically diverse results.
As image prompting evolves, this guide will delve into techniques for writing better text prompts to generate impressive visuals in Stable Diffusion.
Tokenization in Stable Diffusion
Before diving into crafting prompts, it's beneficial to grasp how text prompts are deconstructed for machine understanding. Stable Diffusion's diffusion model efficiently converts text or image prompts from pixel space to latent space. This transition is crucial as latent space allows for the representation of abstract concepts in compressed mathematical forms, significantly lowering memory and computational demands compared to pixel-space models like DALL-E.
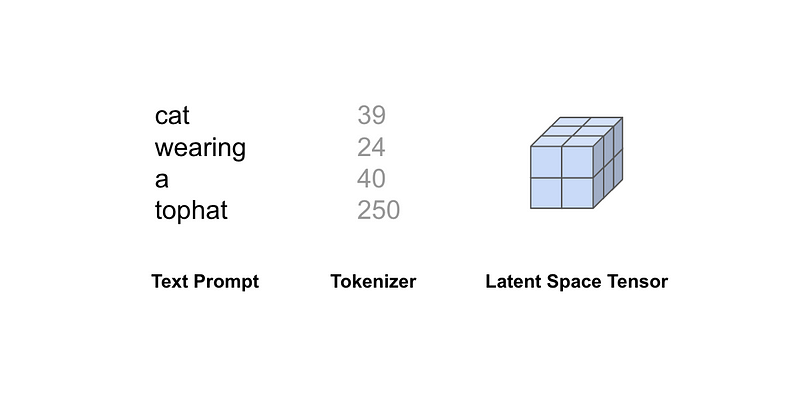
For instance, the prompt “cat wearing a tophat” undergoes tokenization, transforming into a mathematical vector (or embedding). This embedding plays a vital role later in the model’s noise prediction and autoencoder stages. Notably, Stable Diffusion restricts prompts to 75 tokens. However, having 75 words doesn’t necessarily equate to 75 tokens, as concepts can also serve as tokens. Additionally, the tokenizer can only process words it has encountered during training and may break down unfamiliar words to generate understandable embeddings.
Given the significance of tokens in Stable Diffusion, it is essential to be meticulous in how we formulate our prompts.
Tips for Crafting Effective Prompts
Word Order Formatting
The sequence of words in your prompt can greatly impact the generated image. Typically, words placed earlier in the prompt have a more substantial effect on conditioning the latent space compared to those placed later.

Changing the position of a subject can shift the image's focus significantly. Based on my experience, the following structure tends to yield the best results: [Camera/Medium], [Subject], [Indirect Subject], [Details], [Style Modifiers].
Camera/Medium
Starting with the camera or medium in your prompt can significantly guide the diffusion model on the image type desired. For example, specifying camera angles can clarify the viewer’s perspective.

Prompts like “[camera], a man walking in the Sahara desert” can influence how details are depicted, while visual mediums like magazine covers or watercolor paintings can further establish context.
Style Modifiers
Adding style modifiers at the end of your prompt can create varied artistic effects. Historical art movements, film styles, and specific artists can all serve as impactful modifiers.

For example, “portrait painting, a young woman, [style modifier]” can invoke a specific artistic period.
Word Emphasis
As prompts grow longer, it can be harder for the tokenizer to discern what to emphasize. To navigate this, you can use repetition or weighted terms to highlight key ideas.

For example, repeating "cows" in “a field with cows” can increase the number of cows depicted.
Next Steps
In this overview, we’ve examined how word order, camera/medium, style modifiers, and word emphasis work together to enhance the diffusion model's tokenizer, allowing for greater control over the generated imagery. For further refinement, exploring ControlNet or implementing a custom Textual Inversion model could be beneficial.
This video titled "How to Create Perfect AI Art Prompts" provides insights into developing effective prompting strategies.
In "Cracking the Code: How to Prompt for Any AI Art Style," you'll learn various techniques for achieving specific artistic styles in AI-generated art.