Maximizing the Efficiency of Spark's Union Operator: Essential Insights
Written on
Understanding the Spark Union Operator
The union operator serves as a key tool for merging two data frames into one in Apache Spark. This operation is particularly useful when you want to combine rows that share the same column structure. A common scenario involves performing various transformations on different data frames and then merging the results.
While the union operation in Spark is frequently discussed, there are performance considerations that often go unnoticed. Failing to grasp these nuances can lead to significantly increased execution times.
In this article, we will delve into the Apache Spark DataFrame union operator, providing examples, explaining the physical query plan, and outlining optimization strategies.
Union Operator Basics in Spark
Similar to SQL in relational databases, the union operation allows for straightforward row combination. However, it is crucial to ensure that the data frames being merged have the same structure. Specifically:
- The number of columns must match; the union operation will not automatically fill missing columns with NULL values.
- Data types for corresponding columns must be consistent and resolved by their position.
- While the order of column names isn't strictly enforced, the first data frame's column names will be prioritized. This could lead to unexpected results if the order differs. The unionByName method in Spark helps to mitigate this issue.
In Spark, the unionAll function acts as an alias to the union operation without removing duplicates. To mimic SQL's union without duplicates, you must append a distinct operation after the union.
Moreover, you can merge multiple data frames into a single output:
df = df1.union(df2).union(df3)
Performance Challenges with the Union Operator
A common pattern involves dividing a single data frame into several parts, applying unique transformations to each, and finally merging them back together. For instance, if two large tables require joining, the most efficient method in Spark is often the Sort-Merge join. After obtaining the Sort-Merge data frame, it can be divided into subsets, each undergoing different transformations before recombining.
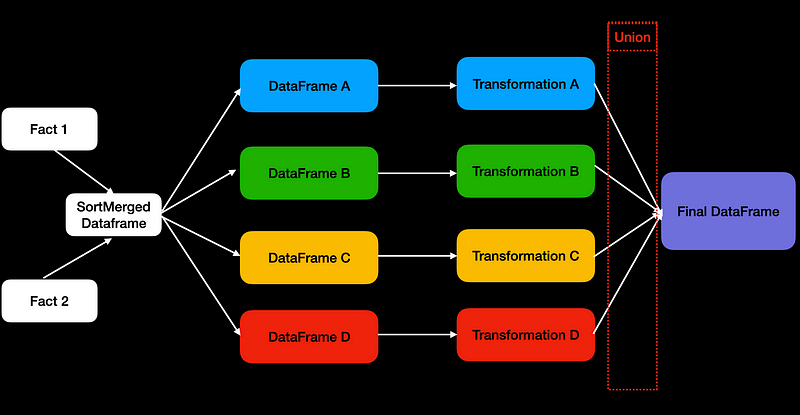
Spark utilizes the Catalyst optimizer, which analyzes your data frame code, optimizes it logically, plans physically, and generates code. Catalyst aims to create an efficient execution plan for your Spark jobs.
While substantial optimizations have been implemented for join operations in recent years, the same cannot be said for union operations. Users often encounter performance bottlenecks with union operators when they do not utilize data frames from entirely distinct sources, as Catalyst does not recognize opportunities to reuse shared data frames.
In scenarios where users conduct union operations on the same data sources, Spark treats each data frame as a separate entity, leading to multiple redundant computations. For example, if we join two large tables four times unnecessarily, it can significantly hinder performance.
Setting Up a Union Operator Example in Spark
Creating a non-optimized physical query plan for the union operator in Spark is relatively simple. Here’s a step-by-step approach:
- Generate two data frames, df1 and df2, containing integers from 1 to 1,000,000.
- Perform an inner join on df1 and df2.
- Split the joined data into two data frames: one for odd numbers and another for even.
- Add a transformation to include a field called magic_value, generated by two placeholder transformations.
- Finally, union the odd and even data frames.
# Create two data frames from 1 to 1000000
df1 = spark.createDataFrame([i for i in range(1000000)], IntegerType())
df2 = spark.createDataFrame([i for i in range(1000000)], IntegerType())
# Perform inner join on df1 and df2
df = df1.join(df2, how="inner", on="value")
# Split the joined result into odd and even number data frames
df_odd = df.filter(df.value % 2 == 1)
df_even = df.filter(df.value % 2 == 0)
# Add a transformation with a field called magic_value
df_odd = df_odd.withColumn("magic_value", df.value + 1)
df_even = df_even.withColumn("magic_value", df.value / 2)
# Union the odd and even number data frames
df_odd.union(df_even).count()
The Directed Acyclic Graph (DAG) for this operation shows that the join operation is performed twice, with the upstream processes appearing nearly identical.
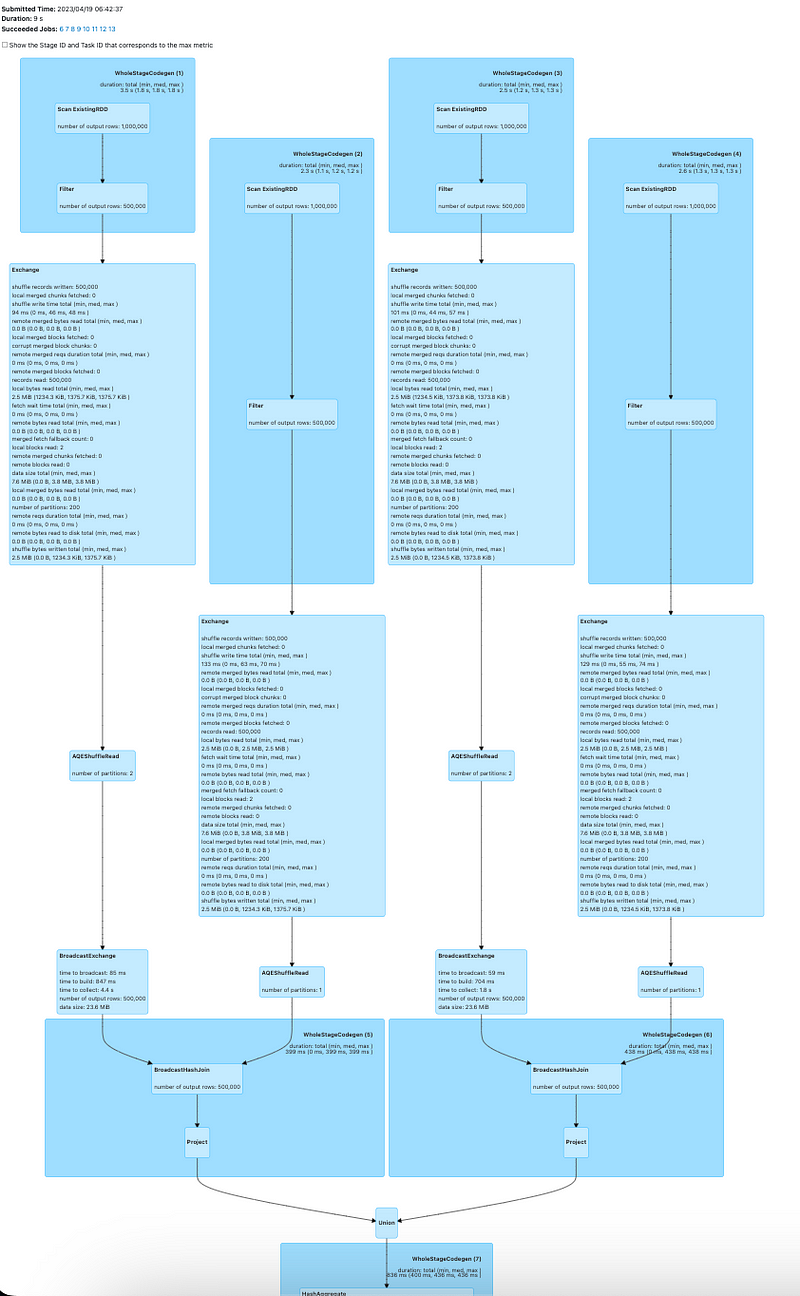
The physical plan will likely reveal numerous stages, indicating inefficiencies.
How to Optimize the Union Operation
Having identified potential bottlenecks, how can we address them? One option is to increase the number of executors to facilitate more concurrent tasks. However, a more effective solution involves guiding Catalyst to reuse the joined data frame from memory.
To enhance performance during the union operation, explicitly invoke a cache to persist the joined data frame in memory. This allows Catalyst to access the data efficiently rather than retrieving it from the source.
The ideal point to add the cache() function is after the join and before filtering:
# Perform inner join on df1 and df2
df = df1.join(df2, how="inner", on="value")
# Add cache here
df.cache()
# Split the joined result into odd and even number data frames
df_odd = df.filter(df.value % 2 == 1)
In this optimized query plan, the presence of InMemoryTableScan indicates that the data frame can be reused, avoiding unnecessary computations.
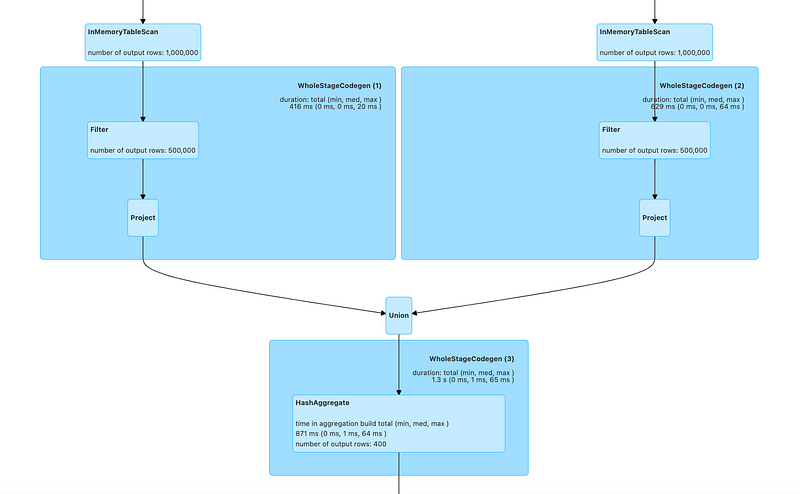
The physical execution plan is now streamlined, with fewer stages required, and both ids leverage InMemoryTableScan effectively.
Final Thoughts
This discussion sheds light on why the union operation can sometimes act as a performance bottleneck in Spark. Due to the limited optimization for the union operator in Catalyst, it’s crucial for users to be aware of these challenges when writing Spark code.
Implementing caching can lead to time savings, but this approach may not be beneficial when dealing with entirely different data sources where no shared caching can be performed.
Insights from Kazuaki Ishizaki's talk — "Goodbye Hell of Unions in Spark SQL" — inspired this exploration, reflecting my experiences with similar issues in my projects.
If you are interested in understanding how to manage data skew in Spark performance, check out my other story:
Deep Dive into Handling Apache Spark Data Skew
The Ultimate Guide To Handle Data Skew In Distributed Compute
towardsdatascience.com