Microsoft and Princeton Unveil Surprising Findings on RL Agents
Written on
Chapter 1: Introduction to Text-Based Games and RL
Text-based games have emerged as a favored platform for experimenting with reinforcement learning (RL) algorithms that interpret and respond to natural language. This research aims to create autonomous agents that can understand textual semantics, enabling them to navigate these games with a human-like comprehension of language.
However, a recent study from Princeton University and Microsoft Research reveals an unexpected finding: current autonomous language-processing agents can achieve impressive scores even when lacking any semantic understanding of the language involved. This suggests that RL agents in text-based games may not be fully utilizing the semantic structures present in the texts they encounter.
To address this limitation and enhance the semantic comprehension of these agents, the research team proposes an inverse dynamics decoder intended to regularize the representation space, promoting a deeper encoding of game-specific semantics.

Section 1.1: Previous Approaches to Language Processing
Various language processing techniques have been employed in text-based games, including word embeddings, neural networks, pretrained language models, and systems designed for open-domain question answering. These methods operate within RL frameworks, treating text games as specific cases of a partially observable Markov decision process (POMDP). In this setup, agents take actions that influence the game environment, aiming to maximize rewards based on the sequence of states and actions. Since these actions and observations are rooted in language, the semantics become tied to the textual inputs and outputs.
In the paper titled "Reading and Acting while Blindfolded: The Need for Semantics in Text Game Agents," the researchers investigate the extent to which current RL agents utilize semantics in text-based games. They examine three scenarios: Minimizing Observation (MIN-OB), Hashing (HASH), and Inverse Dynamics Decoding (INV-DY). For their baseline RL agent, they employ a Deep Reinforcement Relevance Network (DRRN), which learns a Q-network Q?(o, a), encoding observations and action candidates using two distinct gated recurrent units (GRU) encoders, and then aggregating these representations through a multilayer perceptron (MLP) decoder.
At every step in these text games, the action space evolves, providing valuable insights into the current state. In the MIN-OB scenario, the research team reduces the observation to a simple location phrase to isolate action semantics.
Section 1.2: Experimentation and Results
The two GRU encoders within the Q-network ensure that similar texts yield analogous representations. To test the utility of this semantic continuity, the researchers disrupt these encoders by hashing both observation and action texts (HASH), which helps to differentiate various observations and actions.
Finally, the researchers use the INV-DY method to regulate semantics. Since the GRU representations in DRRN are optimized solely for temporal difference loss, there’s a risk that text semantics could degrade during encoding, leading to overfitting to the Q-values. The INV-DY approach helps to regularize both action and observation representations, preventing degeneration by decoding back into the textual domain, thus encouraging the GRU encoders to focus on action-relevant aspects of observations and providing intrinsic motivation for exploration.

Chapter 2: Experimental Findings and Implications
The research team conducted three experiments to assess the impact of different semantic representations across 12 interactive fiction games from the Jericho benchmark.
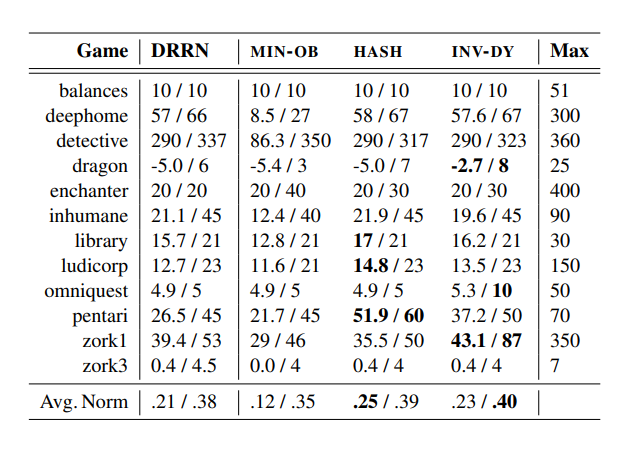
The results highlighted the final score (the average score from the last 100 episodes during training) and the highest score achieved in each game across various models. The average normalized score (the raw score divided by the total game score) was also reported.
The MIN-OB setup managed to achieve comparable maximum scores in many games alongside the base DRRN model but struggled with high episodic scores, underscoring the necessity of utilizing language details to identify distinct observations. Surprisingly, the HASH method nearly doubled the DRRN’s final score on the game PENTARI, suggesting that the DRRN model can perform well without relying on language semantics. For the INV-DY method applied to ZORK I, the maximum score reached was 87, while the other models did not surpass 55. These findings indicate the potential advantages of developing RL agents with enhanced semantic representations and a deeper understanding of natural language.
An earlier version of the paper "Reading and Acting while Blindfolded: The Need for Semantics in Text Game Agents" was presented at the NeurIPS 2020 workshop "Wordplay: When Language Meets Games." The updated research paper can be accessed on arXiv.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Chapter 3: What's New in Microsoft 365
The latest updates from Microsoft 365 bring exciting new features and enhancements that can boost productivity and collaboration.
In this video, you will discover the June updates for Microsoft 365, which include improvements in various applications and services.
Chapter 4: Upcoming Features in Microsoft 365
Stay informed about the latest innovations and enhancements coming to Microsoft 365 in July.
This video highlights the July updates for Microsoft 365, showcasing the new features designed to streamline workflows and enhance user experience.